| Назад: 11.2 Запуск TestComplete из командной строки | Содержание | Дальше: 11.4 Вызов API-функций и функций из DLL |
Использование OCR
Enterprise версия TestComplete содержит плагин OCR (Optical Character Recognition) – система оптического распознавания текста. Возможности OCR позволяют распознавать 52 латинских символа в верхнем и нижнем регистрах, 10 цифр и 31 специальный символ практически любых стилей, размеров и начертаний (жирный, курсив и т.п.). Не поддерживаются национальные символы (например, русские или китайские), а также символы, написанные с помощью специальных шрифтов (например, Wingdings, Webdings и т.д.). Практически невозможно распознавать так называемые капчи (т.е. картинки, которые используются для отличия программ-роботов от живых людей).
Еще один важный аспект использования системы распознавания текстов – это сглаживание шрифтов. Обычно в Windows используется один из способов сглаживания экранных шрифтов, что может повлиять на результаты распознавания текста. Поэтому сглаживание рекомендуется отключить в Панели управления (Start – Settings – Control Panel – Display – Appearance – Effects – Use the following method to smooth edges of screen fonts).
Система распознавания текста может быть полезна при распознавании отсканированных документов или при работе с самописными элементами управления, к свойствам и методам которых невозможно получить доступ в TestComplete.
Теперь рассмотрим пример работы с распознаванием текста. Для этого используется объект OCR, у которого есть только один метод – CreateObject, который принимаетв качестве параметра любой экранный объект и возвращает объект OCRObject. Например, в следующем примере мы создадим OCRObject для окна Калькулятора:
function TestOCR()
{
var wnd;
wnd = Sys.Process(“calc”).Window(“SciCalc”, “Calculator Plus”);
wnd.Activate()
var OCRobj = OCR.CreateObject(wnd);
}
Теперь мы можем распознать весь текст внутри окна Калькулятора с помощью метода GetText:
var OCRobj = OCR.CreateObject(wnd);
var sText = OCRobj.GetText();
Log.Message(“Распознанный текст”, sText);
Результат работы скрипта:
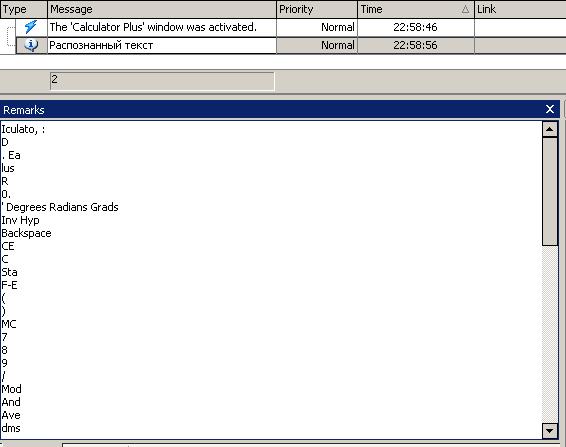
Как видно из результата, практически все надписи на элементах управления распознались хорошо, независимо от цвета текста (а также при том, что было включено сглаживание экранных шрифтов). Проблемы возникли только с заголовком Калькулятора, а также незначительные ошибки вроде буквы I(i заглавная) вместо l (L прописная), однако система OCR в TestComplete не универсальна и подобные ошибки неизбежны.
В следующем примере мы воспользуемся методом FindRectByText для поиска координат текста в окне Калькулятора. Мы будем искать отдельные цифры (например, 7,8 и 9), получать их координаты и затем щелкать мышью по этим координатам. Если все пройдет как надо, то в результате мы введем цифры 789 в Калькулятор. Скрипт:
function TestOCR()
{
var arr = new Array(“7”, “8”, “9”);
var wnd, i;
wnd = Sys.Process(“calc”).Window(“SciCalc”, “Calculator Plus”);
wnd.Activate()
var OCRobj = OCR.CreateObject(wnd);
for(i = 0; i < arr.length; i++)
{
if(OCRobj.FindRectByText(arr[i]))
{
wnd.Click(OCRobj.FoundX, OCRobj.FoundY)
}
else
{
Log.Error(“Text ‘” + arr[i] + “‘ not found”);
}
}
}
Результат:
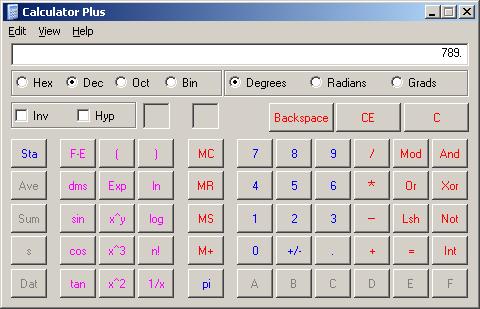
Как видим, все прошло успешно!
Здесь мы не рассматриваем более тонкие настройки для системы распознавания текста OCROptions, в которых можно более точно задавать параметры распознавания, однако обязательно ознакомьтесь с ними в справочной системе TestComplete, если вы планируете часто пользоваться системой OCR.
Кроме того, обратите внимание на то, что хотя TestComplete и не распознает кириллические символы, у нас все же есть возможность частичного распознавания русских текстов в приложении, так как многие символы в русском и английском языках очень похожи. Конечно, такое распознавание будет далеко не полным, однако в некоторых случаях (например, когда надо найти текст в каком-то элементе управления и щелкнуть на нем) этого может оказаться вполне достаточно.
Использование Text Recognition
Кроме возможностей OCR есть еще один способ распознавания текста в неизвестных элементах управления: Text Recognition. Этот способ быстрее и проще, чем оптическое распознавание, однако его возможности ограничены по сравнению с возможностями OCR. Например, если у вас есть картинка, частью которой является текст, – этот текст не будет распознан, так как TestComplete использует Windows API для извлечения текста в Text Recognition.
Для того, чтобы подключить возможность распознавания текста для какого-то элемента управления, необходимо добавить класс этого элемента в список распознаваемых. Для этого щелкнем правой кнопкой мыши по имени проекта в Project Explorer и выберем пункт меню Edit – Properties, после чего в панели справа выберем элемент Open Applications – Text Recognition. Нажмем кнопку Add и впишем имя класса (свойство WndClass) нашего элемента управления (например, для текстового поля Блокнота это будет Edit).
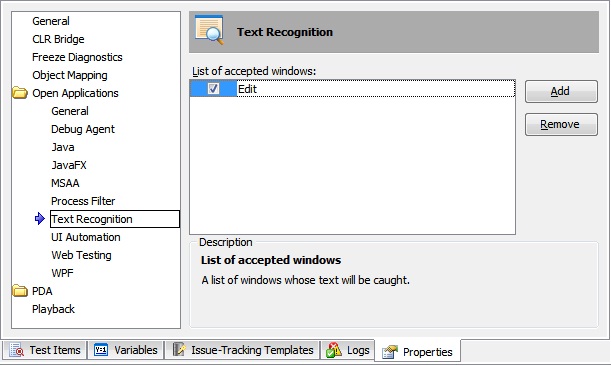
Теперь откроем Object Browser и найдем в дереве нужный нам элемент управления. Если всё сделано правильно, то его значок изменится на новый значок с изображением лупы, а также у него появится дочерний элемент TextObject, в свойстве Text которого и будет находиться весь распознанный текст (для примера в поле ввода я ввел текст «TestComplete tutorial»).
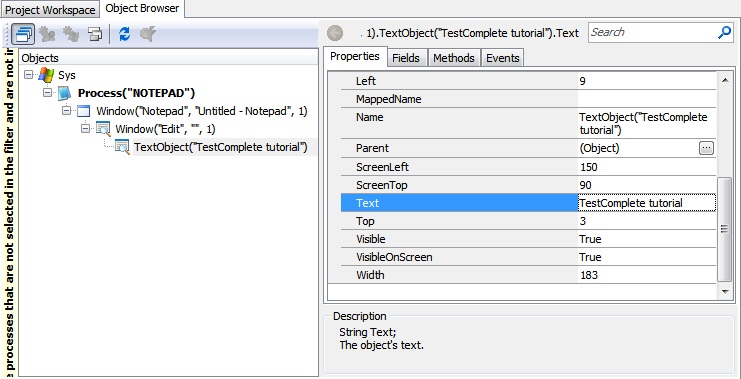
Обращаться к такому элементу нужно так же, как и к любому другому элементу в дереве:
Sys.Process(“NOTEPAD”).Window(“Notepad”, “Untitled – Notepad”, 1).Window(“Edit”, “”, 1).TextObject(“TestComplete tutorial”)
Приведём более сложный пример. Предположим, мы ввели в Блокнот 2 строки текста («TestComplete tutorial» и «One two three») и хотим получить весь текст со всех распознанных элементов. В случае с Блокнотом мы получим 2 разных дочерних элемента, как показано на скриншоте:
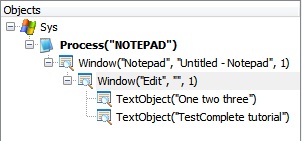
Чтобы получить весь текст, нам необходимо пройтись по всем дочерним элементам текстового поля и получить у них свойство Text, например так.
function TestTextRec()
{
var aText = new Array();
var wnd = Sys.Process(“notepad”).Window(“Notepad”, “*”);
var edit = wnd.Window(“Edit”, “”);
for(var i = 0; i < edit.ChildCount; i++)
{
aText.push(edit.Child(i).Text);
}
Log.Message(“Recognized text”, aText.join(“\n”));
}
Так как метод Text Recognition даёт 100% точность распознавания текста (в отличие от OCR, где могут быть мелкие отличия), то всегда имеет смысл сначала попробовать использовать именно его, а уж если он не подходит – применять возможности OCR.
| Назад: 11.2 Запуск TestComplete из командной строки | Содержание | Дальше: 11.4 Вызов API-функций и функций из DLL |